

RAG Systems
RAG Systems for reliable answers based on your corporate knowledge
A RAG system connects a language model with your own data and delivers answers grounded in verified, current content. Kaufman AIS develops productive RAG architectures for midmarket and larger enterprises in Europe, secure, auditable and along your existing systems.

Why pure language models are not enough in enterprises
A language model that works exclusively on public training knowledge knows neither your contracts, your master data nor your internal processes. It generates plausible but not necessarily correct text. For enterprises this creates a twofold problem.
- Answers sound competent but are not backed by your actual data situation.
- Hallucinations, that is freely invented content, cannot be technically ruled out when the model works without context.
- Current information, for example from the last quarter or a newly signed contract, is completely missing.
- Sensitive data often cannot, for regulatory reasons, be shared with external model providers.
- Business units lose confidence in AI when they have to manually verify every statement.
The Kaufman AIS solution
We build RAG systems that place language models into a clearly controlled corridor. Answers are generated exclusively from your authorized content. Every statement is backed by sources and validated against your actual data situation.
- Answers based on your documents, master data and process descriptions, not on public training knowledge.
- Reduction of hallucinations through verified source grounding and controlled input contexts.
- Complete source attribution so every answer is traceable and auditable.
- Consideration of your role and rights models so every user only sees what they are authorized for.
- Operation in European infrastructure or on premise, depending on compliance requirements.
The benefits of a productive RAG system
A RAG system is more than a chat interface on top of documents. It is a productive layer for knowledge work with tangible effects on quality, speed and traceability.
How a RAG system is technically built
Retrieval Augmented Generation combines classical information retrieval with the generation capability of modern language models. Kaufman AIS implements this chain as a robust enterprise architecture.
Ingestion and preprocessing
Documents, database content and application data are integrated through connectors, normalized, split into meaningful chunks and enriched with metadata. Access rights from the source systems are carried at the level of each chunk.
Semantic indexing with vector database
Every knowledge fragment is stored as a semantic representation in a vector database. The system finds content not through exact terms but through meaning, even when the query is phrased differently from the source document.
Retrieval layer
Upon a query the thematically relevant content is first retrieved from the vector database. Optionally classical search techniques and a knowledge graph complement the result set, for example to capture relationships between entities or regulatory references.
Grounded generation
The language model receives the relevant content as context and produces an answer in which every statement is linked to concrete sources. Results that are not covered by the provided content are marked accordingly.
Evaluation and feedback
Queries, answers and sources are logged and can be analyzed. Business units provide feedback that measurably improves the quality of indexing and answers.
Typical use cases for RAG systems
We apply RAG systems where structured research on large knowledge bases has direct business impact. Industry, finance, logistics, healthcare and professional services are the most frequent application areas.
Service and technical support

Service staff access manuals, ticket histories and engineering knowledge in seconds. Error patterns are matched against documented solutions from past cases.
Sales and proposals

Sales queries product details, references and pricing logic in natural language and works on a unified, current information base.
Compliance and legal

Policies, contracts and regulatory requirements are used as a knowledge base. Business units evaluate cases with traceable sources and reduce manual research.
Engineering and development

Design standards, specifications and lessons learned from earlier projects become directly accessible. Reusable insights stay in the company.
Operations and logistics

Process documentation, exceptions and special cases are available to dispatch and operational teams in a searchable form.
Knowledge-based assistants
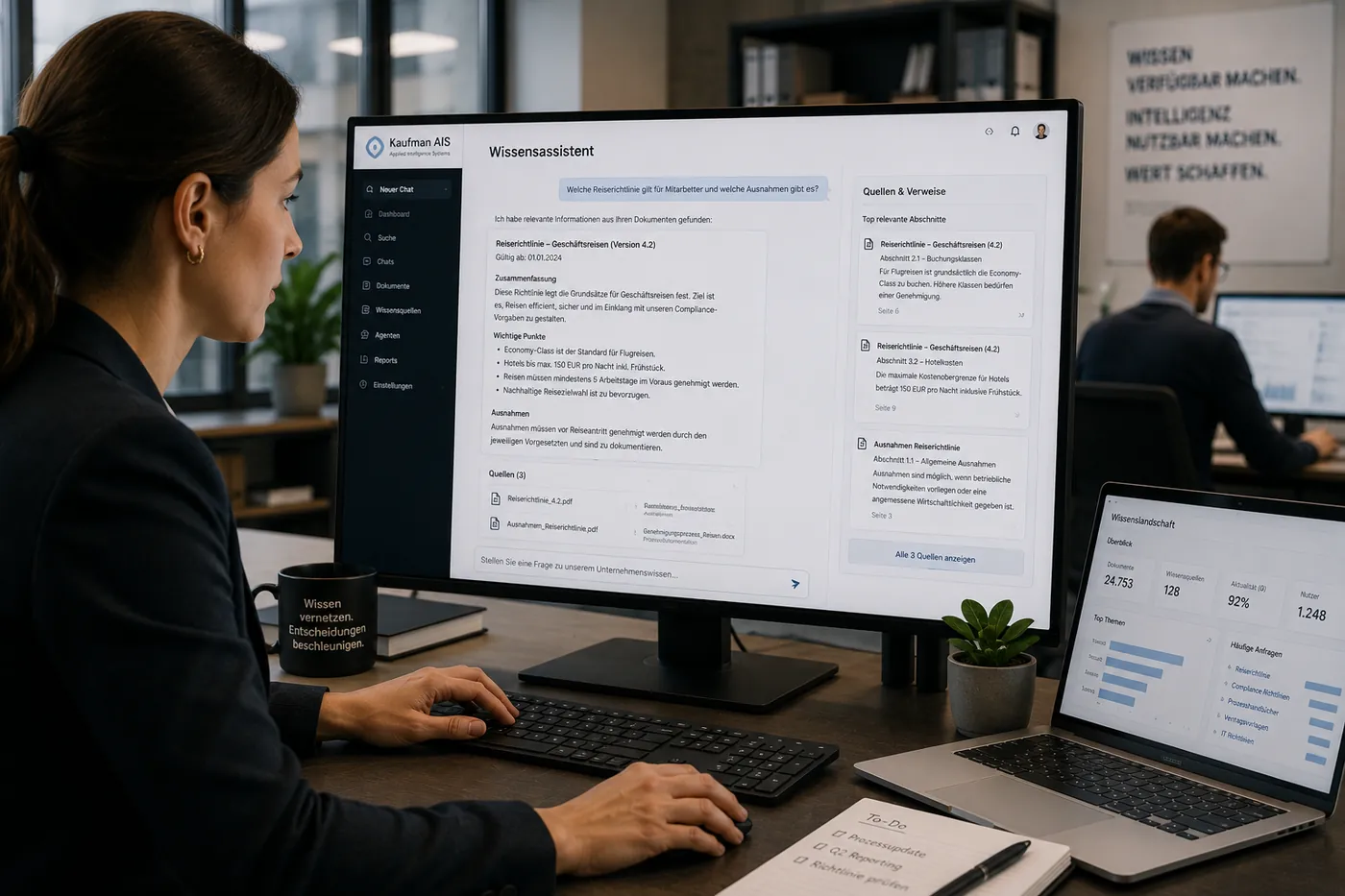
Digital assistants and AI agents build on the RAG layer and take over recurring routine tasks in business units.
Comparing approaches
How a production RAG system differs from generic language models, simple document chatbots and a full enterprise knowledge system.
RAG system vs. alternatives
| Criterion | Kaufman AIS | Language model only | Simple document chat | Enterprise knowledge system |
|---|---|---|---|---|
| Answers based on your company data | No | Partially, single source | ||
| Source references and traceability | No | Rarely structured | ||
| Reduce hallucinations | Critical without context | Partially | ||
| Fast start in one use case | Longer build, more leverage | |||
| Operation in EU or on-premise | Mostly public cloud | Project-dependent |
RAG system and enterprise knowledge system
| Criterion | RAG system | Enterprise knowledge system | Without structured knowledge base |
|---|---|---|---|
| Ideal for clearly scoped use cases | Also, as part of overall architecture | No | |
| Connect many systems and domains | Limited to defined scope | No | |
| Central governance and rights model | Per use case | Company-wide | Not available |
| Foundation for agents and automation | No | ||
| Typical next step | Add more sources | Already integrated knowledge platform | Point solution without expansion |
Security, GDPR and architectural principles
A RAG system processes sensitive content. Kaufman AIS implements security not as an add-on module but as an integral part of the architecture.
- Hosting in European data centres, in private cloud or fully on premise.
- Adoption of role and rights models from the source systems, every answer is checked against the requester's authorization.
- Encryption in transit and at rest in line with current standards.
- Logging of all queries, answers and referenced sources for audits and quality assurance.
- Optional operation with private language models, fully without data flowing to external providers.
- GDPR compliance and support for industry-specific requirements such as BaFin, MDR, ISO 27001 or TISAX.
Frequently asked questions about RAG systems
What is a RAG system?
A RAG system is an architecture that connects language models with a dedicated controlled knowledge base. Queries are first matched against indexed corporate content. The model then generates an answer based exclusively on this verified content.
How secure is a RAG system in enterprise use?
Security is a question of architecture. We operate RAG systems in European infrastructure or on premise, inherit permissions from the source systems and log all access. On request we work fully with private language models so no data flows to external providers.
Which data sources can be integrated?
Typical sources are ERP and CRM systems, document management systems, SharePoint, Microsoft 365, Confluence, wikis, databases, line of business applications and industry-specific systems. Through connectors we integrate structured and unstructured sources without physically moving them.
How does RAG differ from a classical chatbot?
A classical chatbot answers from the general training knowledge of a language model. A RAG system answers based on your own verified content and provides the sources for each answer. This makes it suitable for regulated and knowledge-intensive sectors.
How quickly does a first RAG system become productive?
A clearly scoped use case can typically be brought into production within a few weeks. We start with a pilot application, validate quality and adoption and then expand the system along your roadmap.
Can existing language models be reused?
Yes. When useful we combine RAG systems with models you already use and complement them with private or European model options when compliance requirements demand it.
How up to date does the knowledge base stay?
Through connectors and defined synchronization cycles, sources are updated continuously. Changes in SharePoint, Confluence, ERP or DMS flow into the index without physically copying data. When needed, individual areas can be reindexed manually or event-driven.
What happens if the system delivers a wrong answer?
RAG systems reduce hallucinations by grounding answers in sources. We still validate quality systematically with test questions, feedback loops and sampling. Users see referenced sources and can report content. Answer quality improves continuously as a result.
Can structured data from ERP or databases be integrated?
Yes. In addition to documents we connect tables, master data and transactional information from ERP, CRM and databases. Structured and unstructured sources are combined in one knowledge layer so queries can draw on both.
RAG Systems along your data landscape
We analyze your knowledge sources and use cases and identify where a RAG system has the highest leverage. In a first conversation we jointly design a viable entry point and an architecture that grows with your organization.
Contact
Talk to us about your data landscape knowledge structures and potential applications of intelligent assistant systems within your organization.
