


RAG-systemen
RAG Systems voor betrouwbare antwoorden op basis van uw bedrijfskennis
Een RAG-systeem verbindt een taalmodel met uw eigen gegevens en levert antwoorden op basis van geverifieerde, actuele inhoud. Kaufman AIS ontwikkelt productieve RAG-architecturen voor middelgrote en grotere ondernemingen in Europa, veilig, controleerbaar en aansluitend op uw bestaande systemen.

Waarom pure taalmodellen niet voldoende zijn in ondernemingen
Een taalmodel dat uitsluitend werkt op publieke opleidingskennis kent noch uw contracten, noch uw stamgegevens, noch uw interne processen. Het genereert plausibele, maar niet noodzakelijk correcte tekst. Voor ondernemingen levert dit een tweeledig probleem op.
- De antwoorden klinken competent, maar worden niet ondersteund door uw feitelijke gegevenssituatie.
- Hallucinaties, dat wil zeggen vrij verzonnen inhoud, kunnen technisch niet worden uitgesloten als het model zonder context werkt.
- Actuele informatie, bijvoorbeeld van het laatste kwartaal of een nieuw getekend contract, ontbreekt volledig.
- Gevoelige gegevens kunnen om regelgevingsredenen vaak niet worden gedeeld met externe modelaanbieders.
- Bedrijfseenheden verliezen het vertrouwen in AI wanneer ze elke verklaring handmatig moeten verifiëren.
De Kaufman AIS-oplossing
Wij bouwen RAG-systemen die taalmodellen in een duidelijk gecontroleerde corridor plaatsen. Antwoorden worden uitsluitend gegenereerd op basis van uw geautoriseerde inhoud. Elke verklaring wordt ondersteund door bronnen en gevalideerd aan de hand van uw feitelijke gegevenssituatie.
- Antwoorden op basis van uw documenten, stamgegevens en procesbeschrijvingen, niet op publieke trainingskennis.
- Vermindering van hallucinaties door middel van geverifieerde bronaarding en gecontroleerde invoercontexten.
- Volledige bronvermelding, zodat elk antwoord traceerbaar en controleerbaar is.
- Er wordt rekening gehouden met uw rol- en rechtenmodellen, zodat iedere gebruiker alleen ziet waarvoor hij/zij geautoriseerd is.
- Operatie in de Europese infrastructuur of op locatie, afhankelijk van de compliance-eisen.
De voordelen van een productief RAG-systeem
Een RAG-systeem is meer dan een chatinterface bovenop documenten. Het is een productieve laag voor kenniswerk met tastbare effecten op kwaliteit, snelheid en traceerbaarheid.
Hoe een RAG-systeem technisch is opgebouwd
Retrieval Augmented Generation combineert het klassieke ophalen van informatie met de generatiemogelijkheden van moderne taalmodellen. Kaufman AIS implementeert deze keten als een robuuste enterprise-architectuur.
Inname en voorverwerking
Documenten, database-inhoud en applicatiegegevens worden via connectoren geïntegreerd, genormaliseerd, opgesplitst in betekenisvolle brokken en verrijkt met metadata. Toegangsrechten van de bronsystemen worden op het niveau van elk blok overgedragen.
Semantische indexering met vectordatabase
Elk kennisfragment wordt als semantische representatie opgeslagen in een vectordatabase. Het systeem vindt inhoud niet op basis van exacte termen, maar op basis van de betekenis, zelfs als de vraag anders is geformuleerd dan die van het brondocument.
Ophaallaag
Bij een zoekopdracht wordt eerst de thematisch relevante inhoud uit de vectordatabase opgehaald. Optioneel kunnen klassieke zoektechnieken en een kennisgrafiek de resultatenset aanvullen, bijvoorbeeld om relaties tussen entiteiten of regelgevingsreferenties vast te leggen.
Geaarde generatie
Het taalmodel ontvangt de relevante inhoud als context en levert een antwoord op waarin elke stelling wordt gekoppeld aan concrete bronnen. Resultaten die niet onder de aangeboden inhoud vallen, worden dienovereenkomstig gemarkeerd.
Evaluatie en feedback
Vragen, antwoorden en bronnen worden vastgelegd en kunnen worden geanalyseerd. Bedrijfseenheden geven feedback die de kwaliteit van indexering en antwoorden meetbaar verbetert.
Typische gebruiksscenario's voor RAG-systemen
We passen RAG-systemen toe waarbij gestructureerd onderzoek op grote kennisbanken directe zakelijke impact heeft. Industrie, financiën, logistiek, gezondheidszorg en professionele dienstverlening zijn de meest voorkomende toepassingsgebieden.
Service en technische ondersteuning

Servicepersoneel heeft binnen enkele seconden toegang tot handleidingen, ticketgeschiedenis en technische kennis. Foutpatronen worden vergeleken met gedocumenteerde oplossingen uit eerdere gevallen.
Verkoop en offertes

Sales vraagt productdetails, referenties en prijslogica op in natuurlijke taal en werkt op een uniforme, actuele informatiebasis.
Naleving en juridisch

Beleid, contracten en wettelijke vereisten worden gebruikt als kennisbasis. Business units beoordelen cases met traceerbare bronnen en verminderen handmatig onderzoek.
Techniek en ontwikkeling

Ontwerpnormen, specificaties en lessen uit eerdere projecten worden direct toegankelijk. Herbruikbare inzichten blijven binnen het bedrijf.
Operatie en logistiek

Procesdocumentatie, uitzonderingen en speciale gevallen zijn in doorzoekbare vorm beschikbaar voor expeditie- en operationele teams.
Op kennis gebaseerde assistenten
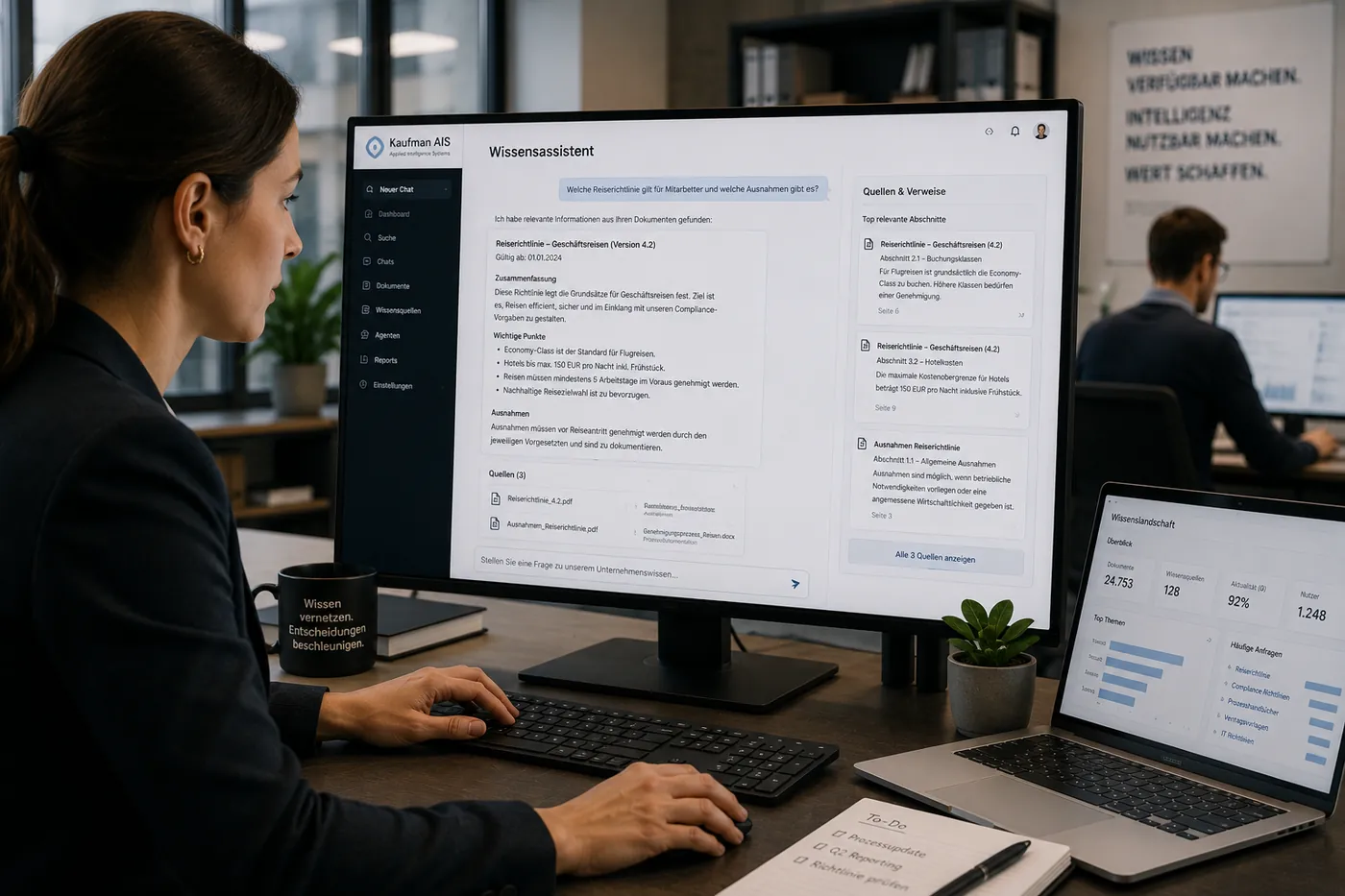
Digitale assistenten en AI-agenten bouwen voort op de RAG-laag en nemen terugkerende routinetaken in bedrijfseenheden over.
Benaderingen vergelijken
Hoe een productie-RAG-systeem verschilt van generieke taalmodellen, eenvoudige documentchatbots en een volledig bedrijfskennissysteem.
RAG-systeem versus alternatieven
| Criterium | Kaufman AIS | Alleen taalmodel | Eenvoudige documentchat | Kennissysteem voor ondernemingen |
|---|---|---|---|---|
| Antwoorden op basis van uw bedrijfsgegevens | No | Gedeeltelijk, één bron | ||
| Bronverwijzingen en traceerbaarheid | No | Zelden gestructureerd | ||
| Verminder hallucinaties | Kritisch zonder context | Gedeeltelijk | ||
| Snelle start in één gebruiksscenario | Langere bouw, meer hefboomwerking | |||
| Operatie in de EU of op locatie | Meestal publieke cloud | Projectafhankelijk |
RAG-systeem en ondernemingskennissysteem
| Criterium | RAG-systeem | Kennissysteem voor ondernemingen | Zonder gestructureerde kennisbank |
|---|---|---|---|
| Ideaal voor duidelijk omschreven gebruiksscenario's | Ook als onderdeel van de algehele architectuur | No | |
| Verbind veel systemen en domeinen | Beperkt tot gedefinieerd bereik | No | |
| Centraal bestuurs- en rechtenmodel | Per gebruiksscenario | Bedrijfsbreed | Niet beschikbaar |
| Basis voor agenten en automatisering | No | ||
| Typische volgende stap | Voeg meer bronnen toe | Reeds geïntegreerd kennisplatform | Puntoplossing zonder expansie |
Beveiliging, AVG en architectuurprincipes
Een RAG-systeem verwerkt gevoelige inhoud. Kaufman AIS implementeert beveiliging niet als een add-on-module, maar als een integraal onderdeel van de architectuur.
- Hosting in Europese datacenters, in private cloud of volledig on premise.
- Overname van rol- en rechtenmodellen uit de bronsystemen, ieder antwoord wordt getoetst aan de autorisatie van de aanvrager.
- Versleuteling tijdens verzending en in rust in overeenstemming met de huidige normen.
- Registratie van alle vragen, antwoorden en bronnen waarnaar wordt verwezen voor audits en kwaliteitsborging.
- Optionele werking met privétaalmodellen, volledig zonder dat er gegevens naar externe providers stromen.
- AVG-compliance en ondersteuning voor branchespecifieke vereisten zoals BaFin, MDR, ISO 27001 of TISAX.
Veelgestelde vragen over RAG-systemen
Wat is een RAG-systeem?
Een RAG-systeem is een architectuur die taalmodellen verbindt met een speciale gecontroleerde kennisbank. Zoekopdrachten worden eerst vergeleken met geïndexeerde bedrijfsinhoud. Het model genereert vervolgens een antwoord uitsluitend op basis van deze geverifieerde inhoud.
Hoe veilig is een RAG-systeem bij zakelijk gebruik?
Beveiliging is een kwestie van architectuur. We gebruiken RAG-systemen in de Europese infrastructuur of op locatie, nemen de rechten over van de bronsystemen en loggen alle toegang. Op verzoek werken wij volledig met privétaalmodellen waardoor er geen datastromen naar externe aanbieders plaatsvinden.
Welke databronnen kunnen worden geïntegreerd?
Typische bronnen zijn ERP- en CRM-systemen, documentbeheersystemen, SharePoint, Microsoft 365, Confluence, wiki's, databases, branchespecifieke applicaties en branchespecifieke systemen. Via connectoren integreren we gestructureerde en ongestructureerde bronnen zonder ze fysiek te verplaatsen.
Waarin verschilt RAG van een klassieke chatbot?
Een klassieke chatbot antwoordt vanuit de algemene trainingskennis van een taalmodel. Een RAG-systeem antwoordt op basis van uw eigen geverifieerde inhoud en levert de bronnen voor elk antwoord. Dit maakt het geschikt voor gereguleerde en kennisintensieve sectoren.
Hoe snel wordt een eerste RAG-systeem productief?
Een duidelijk omschreven use case kan doorgaans binnen enkele weken in productie worden genomen. We beginnen met een pilottoepassing, valideren de kwaliteit en acceptatie en breiden het systeem vervolgens uit volgens uw roadmap.
Kunnen bestaande taalmodellen worden hergebruikt?
Ja. Wanneer dit nuttig is, combineren we RAG-systemen met modellen die u al gebruikt en vullen we deze aan met particuliere of Europese modelopties wanneer de nalevingsvereisten dit vereisen.
Hoe actueel blijft de kennisbank?
Via connectoren en gedefinieerde synchronisatiecycli worden bronnen continu bijgewerkt. Wijzigingen in SharePoint, Confluence, ERP of DMS vloeien naar de index zonder dat gegevens fysiek worden gekopieerd. Indien nodig kunnen individuele gebieden handmatig of op basis van gebeurtenissen opnieuw worden geïndexeerd.
Wat gebeurt er als het systeem een verkeerd antwoord geeft?
RAG-systemen verminderen hallucinaties door antwoorden in bronnen te baseren. We valideren de kwaliteit nog steeds systematisch met testvragen, feedbackloops en sampling. Gebruikers zien bronnen waarnaar wordt verwezen en kunnen inhoud rapporteren. De antwoordkwaliteit verbetert daardoor voortdurend.
Kunnen gestructureerde gegevens uit ERP of databases worden geïntegreerd?
Ja. Naast documenten verbinden wij tabellen, masterdata en transactie-informatie uit ERP, CRM en databases. Gestructureerde en ongestructureerde bronnen worden gecombineerd in één kennislaag, zodat zoekopdrachten uit beide kunnen putten.
RAG Systems langs uw datalandschap
We analyseren uw kennisbronnen en use cases en identificeren waar een RAG-systeem de hoogste hefboomwerking heeft. In een eerste gesprek ontwerpen we samen een levensvatbaar instappunt en een architectuur die meegroeit met uw organisatie.
Contact
Praat met ons over uw kennisstructuren in het datalandschap en mogelijke toepassingen van intelligente assistent-systemen binnen uw organisatie.
