


Systèmes RAG
Systèmes RAG pour des réponses fiables fondées sur la connaissance de votre entreprise
Un système RAG relie un modèle de langage à vos propres données et livre des réponses ancrées dans des contenus vérifiés et actuels. Kaufman AIS développe des architectures RAG productives pour le midmarket et les grands comptes en Europe, sécurisées, auditables et alignées sur vos systèmes existants.

Pourquoi les modèles de langage seuls ne suffisent pas en entreprise
Un modèle de langage travaillant exclusivement sur des connaissances publiques d’entraînement ne connaît ni vos contrats, ni vos données de référence, ni vos processus internes. Il génère des textes plausibles mais pas nécessairement corrects. Pour les entreprises cela crée un double problème.
- Les réponses paraissent compétentes mais ne sont pas couvertes par votre situation réelle de données.
- Les hallucinations, c’est à dire des contenus inventés, ne peuvent être techniquement exclues lorsque le modèle travaille sans contexte.
- Les informations actuelles, par exemple du dernier trimestre ou d’un contrat fraîchement signé, manquent totalement.
- Les données sensibles ne peuvent souvent, pour des raisons réglementaires, être confiées à des fournisseurs externes.
- Les métiers perdent confiance dans l’IA s’ils doivent vérifier manuellement chaque affirmation.
La solution Kaufman AIS
Nous construisons des systèmes RAG qui placent les modèles de langage dans un couloir clairement contrôlé. Les réponses sont générées exclusivement à partir de vos contenus autorisés. Chaque affirmation est appuyée par des sources et confrontée à votre situation réelle de données.
- Réponses fondées sur vos documents, données de référence et descriptions de processus, et non sur des connaissances publiques d’entraînement.
- Réduction des hallucinations par un ancrage source vérifié et des contextes d’entrée contrôlés.
- Attribution complète des sources, afin que chaque réponse soit traçable et auditable.
- Prise en compte de vos modèles de rôles et de droits, pour que chaque utilisateur ne voie que ce pour quoi il est habilité.
- Exploitation en infrastructure européenne ou on premise selon les exigences de conformité.
Les bénéfices d’un système RAG productif
Un système RAG est plus qu’une interface de chat sur des documents. C’est une couche productive pour le travail de connaissance avec des effets tangibles sur qualité, rapidité et traçabilité.
Comment un système RAG est il construit techniquement
La Retrieval Augmented Generation combine la recherche d’information classique avec la capacité générative des modèles de langage modernes. Kaufman AIS implémente cette chaîne comme une architecture d’entreprise robuste.
Ingestion et prétraitement
Documents, contenus de bases de données et données applicatives sont intégrés via des connecteurs, normalisés, découpés en fragments pertinents et enrichis de métadonnées. Les droits d’accès des systèmes sources sont portés au niveau de chaque fragment.
Indexation sémantique avec base vectorielle
Chaque fragment de connaissance est stocké comme représentation sémantique dans une base vectorielle. Le système trouve le contenu non par des termes exacts mais par le sens, même lorsque la requête est formulée différemment du document source.
Couche de retrieval
Lors d’une requête, les contenus thématiquement pertinents sont d’abord récupérés depuis la base vectorielle. En option, des techniques de recherche classiques et un knowledge graph complètent l’ensemble des résultats, par exemple pour capter les relations entre entités ou les références réglementaires.
Génération ancrée sur les sources
Le modèle de langage reçoit les contenus pertinents comme contexte et produit une réponse dans laquelle chaque affirmation est liée à des sources concrètes. Les résultats non couverts par les contenus fournis sont marqués comme tels.
Évaluation et feedback
Requêtes, réponses et sources sont journalisées et peuvent être analysées. Les métiers fournissent un feedback qui améliore mesurablement la qualité de l’indexation et des réponses.
Cas d’usage typiques des systèmes RAG
Nous appliquons les systèmes RAG là où une recherche structurée sur de grandes bases de connaissances a un impact business direct. Industrie, finance, logistique, santé et services professionnels sont les domaines d’application les plus fréquents.
Service et support technique

Le personnel de service accède en quelques secondes aux manuels, historiques de tickets et savoir d’ingénierie. Les images d’erreur sont confrontées à des solutions documentées issues de cas passés.
Ventes et offres

La vente interroge en langage naturel détails produit, références et logiques de prix et travaille sur une base d’information unifiée et actuelle.
Conformité et juridique

Politiques, contrats et exigences réglementaires servent de base de connaissances. Les métiers évaluent des cas avec des sources traçables et réduisent la recherche manuelle.
Ingénierie et développement

Standards de conception, spécifications et retours d’expérience de projets antérieurs deviennent directement accessibles. Les enseignements réutilisables restent dans l’entreprise.
Opérations et logistique

Documentation de processus, exceptions et cas particuliers sont à disposition des équipes de dispatching et opérationnelles sous une forme recherchable.
Assistants basés sur la connaissance
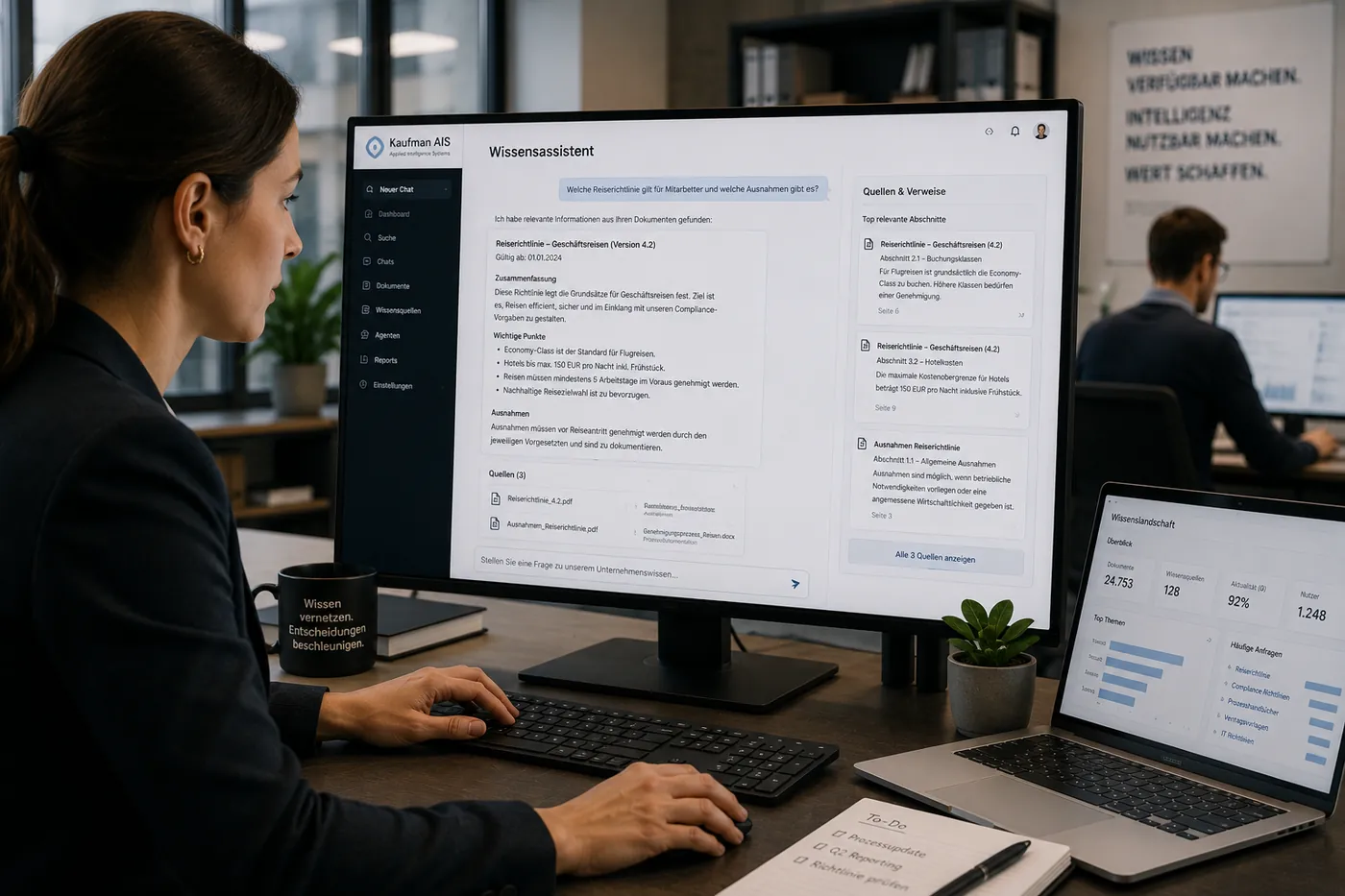
Les assistants numériques et agents IA s’appuient sur la couche RAG et prennent en charge les tâches routinières récurrentes des métiers.
Sécurité, RGPD et principes d’architecture
Un système RAG traite des contenus sensibles. Kaufman AIS implémente la sécurité non comme un module additionnel mais comme une partie intégrante de l’architecture.
- Hébergement en datacenters européens, en cloud privé ou entièrement on premise.
- Reprise des modèles de rôles et de droits des systèmes sources, chaque réponse est vérifiée contre l’autorisation du demandeur.
- Chiffrement en transit et au repos conformément aux standards actuels.
- Journalisation de l’ensemble des requêtes, réponses et sources référencées pour audit et assurance qualité.
- Exploitation optionnelle avec des modèles de langage privés, sans fuite de données vers des fournisseurs externes.
- Conformité RGPD et prise en charge des exigences sectorielles telles que BaFin, MDR, ISO 27001 ou TISAX.
Questions fréquentes sur les systèmes RAG
Qu’est ce qu’un système RAG ?
Un système RAG est une architecture qui relie des modèles de langage à une base de connaissances propre et contrôlée. Les requêtes sont d’abord confrontées aux contenus d’entreprise indexés. Le modèle génère ensuite une réponse fondée exclusivement sur ces contenus vérifiés.
Quelle est la sécurité d’un système RAG en entreprise ?
La sécurité est une question d’architecture. Nous exploitons les systèmes RAG en infrastructure européenne ou on premise, reprenons les autorisations des systèmes sources et journalisons tous les accès. Sur demande, nous travaillons entièrement avec des modèles de langage privés afin qu’aucune donnée ne sorte vers des fournisseurs externes.
Quelles sources de données peuvent être intégrées ?
Sources typiques — systèmes ERP et CRM, gestion documentaire, SharePoint, Microsoft 365, Confluence, wikis, bases de données, applications métier et systèmes sectoriels. Via des connecteurs, nous intégrons des sources structurées et non structurées sans les déplacer physiquement.
En quoi le RAG diffère il d’un chatbot classique ?
Un chatbot classique répond à partir des connaissances générales d’entraînement d’un modèle de langage. Un système RAG répond à partir de vos propres contenus vérifiés et indique les sources de chaque réponse. Il convient ainsi aux secteurs régulés et à forte intensité de connaissance.
À quelle vitesse un premier système RAG est il productif ?
Un cas d’usage clairement délimité peut typiquement être mis en production en quelques semaines. Nous commençons par une application pilote, validons qualité et adoption puis étendons le système le long de votre feuille de route.
Les modèles de langage existants peuvent ils être réutilisés ?
Oui. Lorsque c’est pertinent, nous combinons les systèmes RAG avec des modèles que vous utilisez déjà et les complétons par des options privées ou européennes lorsque la conformité l’exige.
Comment la base de connaissances reste t elle à jour ?
Via des connecteurs et des cycles de synchronisation définis, les sources sont mises à jour en continu. Les changements dans SharePoint, Confluence, ERP ou GED alimentent l’index sans copie physique des données. Si besoin, des domaines peuvent être réindexés manuellement ou par événement.
Que se passe t il si le système fournit une mauvaise réponse ?
Les systèmes RAG réduisent les hallucinations en ancrant les réponses aux sources. Nous validons toutefois la qualité avec des questions tests, des boucles de retour et des échantillonnages. Les utilisateurs voient les sources référencées et peuvent signaler un contenu. La qualité s’améliore ainsi en continu.
Les données structurées d’ERP ou de bases peuvent elles être intégrées ?
Oui. Outre les documents, nous connectons tableaux, données de référence et informations transactionnelles issues d’ERP, CRM et bases. Sources structurées et non structurées convergent dans une couche de connaissances commune.
Systèmes RAG le long de votre paysage de données
Nous analysons vos sources de connaissances et cas d’usage et identifions où un système RAG offre le plus de levier. Lors d’un premier échange, nous concevons ensemble une entrée viable et une architecture qui grandit avec votre organisation.
Contact
Échangez avec nous sur votre écosystème de données vos structures de connaissances et les cas d’usage possibles des systèmes d’assistance intelligents dans votre organisation.
